Como comenté hace tiempo, una de las ideas que tenía para este año es empezar a tratar el tema de la ciencia de datos para Administraciones Públicas. Igual que cuando empezó este proyecto me dedicaba a escribir sobre los conceptos que iba aprendiendo de analítica web, ahora, que me pongo con esta disciplina, mi idea es tender la mano a quien lee el blog para que me acompañe. Muchas de las cosas que empiezo a estudiar las conozco por diversos motivos: estudios, experiencia profesional, aficiones o curiosidad.
El caso es que quiero hacer un trabajo que abarque todo lo necesario para entender este campo, su posible aplicación en las AAPP y cómo llevarlo adelante. Evidentemente hay gente que hace artículos más avanzados porque saben más, y porque van a profundizar. Yo lo que quiero es divulgar de 0 hasta donde llegue. Así que vamos a empezar desde el principio. Y el principio son los tipos de datos que hay.
Por qué hablamos de tipos de datos
La cantidad de datos que hay es absolutamente ingente y cada vez mayor. Hay tres motivos por los que hay que conocer los tipos de datos que podemos usar:
- Para identificar datos. Esto es lo primero: hay datos en todos sitios, lo que pasa es que parte de ellos no son tan evidentes. Por ejemplo, cuando pensamos en datos imaginamos enormes tablas y hojas de cálculo; sin embargo, un documento contiene muchos datos que podemos aprovechar.
- Para saber qué datos tenemos que buscar. Un segundo punto es saber qué datos son los más adecuados para lo que queremos averiguar. Si tenemos la intención de conocer la evolución de casos del COVID necesitaremos datos muy diferentes a los que buscaríamos para saber si las cuentas de una Administración son correctas.
- Para saber cómo tenemos que tratar los datos. Los tipos de datos que utilizamos presentan una serie de requisitos y posibilidades específicas. Según esta configuración tendremos que usar determinados recursos y podremos explotar ciertas probabilidades. En nuestros ejemplos del COVID y las cuentas de una Administración, cada uno tendrá unos requisitos téncicos y operativos (Cantidad de información, periodos de análisis, velocidad de proceso, pervivencia del dato) y posibilidades (indicativas, predictivas, de control) diferentes.
- Para pensar qué datos necesitamos. Por último, y relacionado con lo anterior, los tipos de datos nos ayudan a saber qué es exactamente lo que estamos buscando. En el trabajo de los datos normalmente tienes que conformarte con lo mejor que puedes conseguir, pero lo primero es preguntarse acerca de lo que necesitas saber. No es lo mismo saber lo que ha pasado que suponer lo que pasará, que saberlo de una persona, o saberlo de un colectivo.
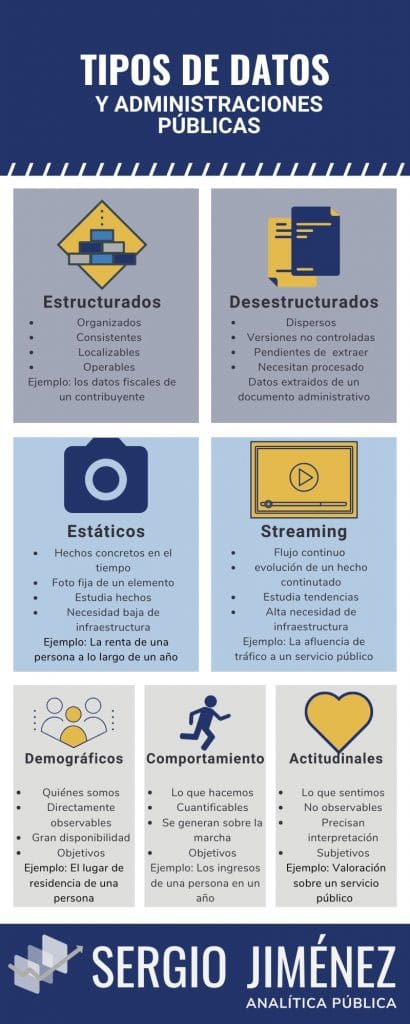
Tipos de datos por su composición
El primer tipo de clasificaciónhacer referencia a cómo se componen y articulan los datos.
Datos estructurados
Los datos estructurados es lo que tenemos prácticamente todos en mente cuando hablamos de datos. Se trata de datos que:
- Estan organizados. Es decir, clasificados, ordenados y separados, de manera que podemos encontrar el dato preciso con una búsqueda simple
- Son consistentes. Mantienen el mismo valor en diferentes circunstancias y localizaciones. Es decir, que cuando buscamos un valor en un momento circunstancias dadas (por ejemplo en una fecha y con unos parámetros definidos) será el mismo que si repetimos la búsqueda más adelante en el tiempo y con otros parámetros equivalentes.
Los datos estructurados son los que se gestionan y operan de manera más fácil. El problema es que, hasta hace relativamente poco, la estructuración de los datos no era algo tan común o sencillo. Es decir, hasta que hemos tenido sistemas en los que la captura de datos (cuando cogemos un elemento y lo convertimos en un dato, se llama captura) sea fácilmente estructurada, el trabajo de estructuracion era cuestión de pasar esos datos de distintas manera que van de sistemas de troquelado a trabajo manual. De hecho, la facilidad para capturar los datos de manera directamente estructurada (como hace por ejemplo la Agencia Tributaria cuando usamos PADRE para hacer la declaración) o la facilidad en esta estructuración (las declaraciones antiguas con sus sistemas de casillero) facilitan pasar a fases posteriores de procesado y operacionalización.
Datos desestructurados
Los datos desestructurados están en formato o formatos libres, dispersos y sin una categorización previa. Es decir, la gran mayoría de los datos que hay por ahí, están desestructurados. Esto incluye desde el tiempo que vamos andando por la calle, a los documentos que contiene un expediente o una oferta para una licitación. En el caso de la Administración tenemos una ingente cantidad de datos desestructurados en los documentos administrativos.
Extraer datos desestructurados es enormemente complicado y costoso, incluso cuando las condiciones están más o menos controladas (como por ejemplo, en las plantillas de una comunicación administrativa donde un mismo término está reflejado siempre en el mismo punto en la misma frase). La libertad hace que tanto la casuística que presenta como la posible retroactividad (¿desde dónde empezamos a estructrar?) implica un análisis muy extenso y procesos de captura muy variados.
Cuando hablabamos en uno de los «analitica publica besties» de orientación a datos o a documentos, hablamos precisamente de esta cuestión: si trabajamos sobre datos estructurados que generan documentos o si utilizamos documentos de los que tenemos que extraer datos.
Como decía, la gran mayoría de los datos en la administración está desestructurado. Pese a que hay avances gracias a los formularios, gestores de expedientes que permiten jugar a dos niveles y demás, esto ralentiza la asimilación de la automatización.
Por otro lado hay que considerar que, en muchos casos damos el salto de desestructurados a estructurados (por ejemplo, un expediente que genera un documento contable) que, en muchos casos (la mayoría) no corresponden a una integración manual, de manera que el control de los datos requieren control a los dos niveles (es decir, a la hora de generar el documento y a la hora de estructurar el dato de manera manual).
Tipos de datos por adquisición
La adquisición del dato (o su continuidad) es el segundo elemento a tener en cuenta. Es un fenómeno relativamente nuevo dado que los datos dinámicos a tiempo real son una criatura bastante nueva.
Datos estáticos
La información estática es la manera tradicional de entender los datos y la información. Esto se debe a dos motivos. En primer lugar por la concepción convencional de medir hechos concretos y determinados en el tiempo. Cuanto ganas en un año, cuántos impuestos pagas, cuánto propone esta empresa en este concurso público… Por otro lado, incluso cuando quisiéramos tener datos como un flujo continuos de algo (por ejemplo, la renta de una persona) el control continuo y a tiempo real no es posible ni, en este caso, posiblemente deseable.
Los datos estáticos muestran una foto fija, lo que exige acotar exactamente qué es lo que estamos mirando y en qué momento esa foto es la más fiel posible. En muchos casos esto es fácil porque está claro cuando ocurre el evento (por ejemplo, una defunción) o porque la administración fija el momento de la foto (el año fiscal, el cierre de ofertas…). En otros esto es más complicado(por ejemplo, el grado de minusvalía de una persona), así que hay que recurrir a criterios en muchos casos externos al dato.
Datos en streaming
Los datos dinámicos y a tiempo real son una relativa «novedad». Son aquellos que recogemos de manera continua y que permiten una gran cantidad de usos relativos tanto a su valor comparativo y de análisis como de proyección a futuro. Es el caso de cuestiones como el tráfico en las ciudades, datos de salud, de posicionamiento, acceso a servicios, consumo de contenidos, etc.
Los datos en streaming tienen una peculiaridad que les hace muy especiales: por su naturaleza son prácticamente infinitos. Esto requiere hacer un trabajo de selección bastante cuidadosa en tres niveles:
- El «grano» temporal. Qué elementos temporales vamos a considerar como elemento base ¿el día? ¿la semana? ¿El segundo? Como una manta corta, cuanto más pequeño es el grano, más cantidad de almacenamiento y procesado vamos a definir
- La antigüedad del datos. ¿Hasta qué punto o fecha nos remontamos para el análisis? Tener datos en un continuo supone tener que decidir desde qué periodo observamos los elementos a tratar.
- Puntos de control. Los datos pueden ser continuos, pero las acciones de supervisión y control son limitados (uno puede mirar los datos en un momento o momentos determinados).
Los datos en tiempo real tienen en realidad tres funciones y media básicas:
- potencian la visualización de información en la cultura de la organización
- Permiten monitorizar los eventos. No se trata tanto de analizar como de saber qué pasa cuando.
- Análisis de pautas y tendencias a lo largo del tiempo
- La media (aunque es enormemente importante) y derivada de la anterior: es la que permite a las Inteligencias Artificiales sacar su máximo esplendor a la hora de aprender (y anticipar) tendencias.
Es decir, la utilidad a nivel analítico es algo menor (aunque no en el control), pero es crítica para la creación de la IA en la organización. Esto es importante porque, a fin de cuentas, el coste en infraestructura es enormemente alto.
Tipos de datos por categorías
El último bloque es la categoría de datos que podemos usar corresponde al aspecto al que hace referencia (en lo que se refiere a personas).
Datos demográficos
Los datos demográficos son los que hablan de quiénes son las personas. Estos no son exclusivamente los que podemos entender (edad, talla, etcétera). Esto incluye cuestiones relativas a ubicación geográfica, ingresos y renta, cuestiones laborales, etc. Prácticamente casi todo lo que entendemos como «datos personales» entran en este saco. Digo entendemos porque cualquiera que se tope con el RGPD sabe que un dato personal es cualquier cosilla que sirve para identificar a una persona.
La administración tiene una ingente cantidad de datos demográficos, y además de altísima fidelidad. Aspectos como el censo, el padrón, hacienda, los datos laborales, etc. son datos que se tienen y que se explotan de manera bastante frecuente. Que te llegue
Datos de comportamiento
Es el segundo nivel son los datos relacionados con el comportamiento real de los individuos. Son datos que se generan «solos» siempre y cuando tengamos capacidad de capturarlos o generarlos automáticamente. Cuando pagamos o cobramos algo, cuando realizamos un trámite, solicitamos una ayuda o una cita, son elementos de comportamiento que podemos registrar. Se trata, por lo tanto, de elementos objetivos.
En el caso de las AAPP tenemos también una cantidad de datos de comportamiento, tanto propios generados en la interacción de la Administración como por la parte de terceros (por ejemplo, la facturación, o la información fiscal) y suele utilizarlo de manera más o menos desigual. Hay casos en los que los datos de comportamiento se tratan de manera sistemática tanto para realizar acciones (recaudar impuestos) como para iniciar pesquisas (inspecciones fiscales).
La ventaja es la afinidad de esta objetividad del dato con uno de los principios de la acción pública: la imparcialidad y (valga la redundancia) la objetividad. En realidad es difícilmente discutible una decisión basada en hechos reales. Sin embargo, una parte importante de lo que podemos usar en el análisis de datos viene de los siguientes.
Actitudinales
Los datos actitudinales son los que podemos extraer del pensamiento y sentimiento de las personas. Uno puede saber, por ejemplo, si se tramitan muchas facturas electrónicas, pero eso es muy distinto de lo que piensan las personas que tienen que presentarlas. Sin embargo, vale la pena el esfuerzo de obtener y tratar estos datos porque el impacto de los mismos es extremadamente directo. Es decir, yo puedo haber presentado una factura electrónica, (y la estadística lo contará) pero yo siempre recordaré (y puede que cuente a la gente) que es una experiencia incómoda y que vale la pena pagar para que lo haga otra persona en tu lugar (y quizá ese post tenga bastantes visitas, lo que me da que pensar que no es una excepción.)
Los datos actitudinales tienen dos dificultades añadidas:
- Son difícilmente capturables. No sólo es que capturar en un dato una sensación o un sentimiento es complicado, es que, además, sólo nos podemos fiar de lo que nos dicen. Yo puedo decir en un momento de frustración que la factura electrónica es lo peor que me ha pasado, cuando, en realidad, en 6 meses solo lo veré como algo muy incómodo, pero desde luego, no comparable a presentar la declaración de la renta siendo autónomo.
- Son altamente subjetivos. La subjetividad tiene un problema y no es precisamente que sea referente al sujeto (estamos estudiando sujetos), sino a que cada persona tiene su escala de valoración. A mi me puede satisfacer igual que a mi pareja hacer un trámite, pero puede que yo sea más generoso puntuando la experiencia y sensación que ella (o al revés). Esto dificulta la baremación real (y la comparación).
En muchas ocasiones los datos de comportamiento nos indican actitudes (por ejemplo, cuando Netflix analiza el tiempo que tardamos en ver La Casa de Papel).
Los datos actitudinales han ido aumentando su importancia, sobre todo en el sector privado. Facebook es una buena cuenta de ello. En el sector público se han incorporado desde la introducción de políticas de calidad, pero uno no puede evitar la sensación de que no se usan tanto para tomar decisiones que como para avalar acciones. En todo caso, el impacto de una gestión efectiva es más alto porque afecta directamente no a los hechos, sino a la percepción y valoración del público.
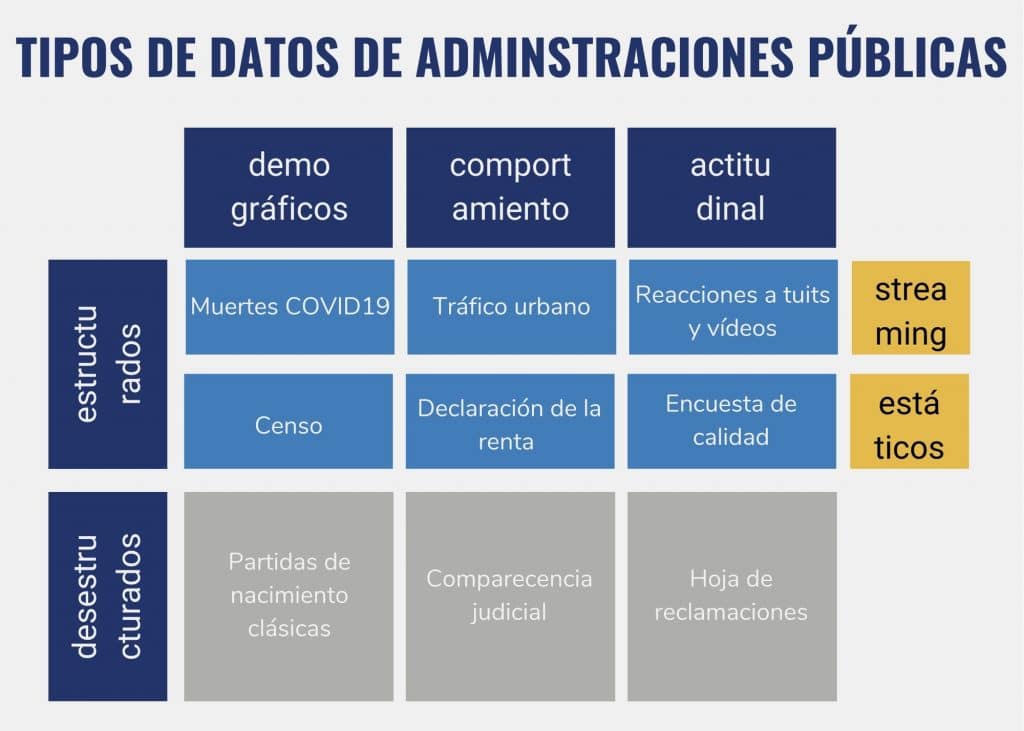
Conclusiones
El uso de los datos es uno de los desafíos de las Administraciones. Hasta la fecha tiene tres retos importantes:
- ser capaz de explotar e integrar todos los que tiene (estructurados y no)
- aprovechar y contextualizar los avances tecnológicos más recientes. Es decir, aprovechar cuestiones como el IoT pero no basarse en el gadget más nuevo para todo, dado que en ocasiones, otros anteriores son más adecuados.
- Ampliar el uso a elementos: tanto en uso de tipos de datos conocidos (demográficos y de comportamiento) de maneras diferentes, a incorporar nuevos tipos.
En resumen, hay múltiples posibilidades de aplicar los datos y contextos para hacerlos. La cuestión es explorar aquellos enfoques que puedan aportar a la administración y al bien social un mejor resultado.

{kind=link}