Hace un tiempo hablamos del uso de la eAdministración durante el confinamiento con los datos de Clave. Descubrimos que sólo los servicios de identificación con certificado tuvo un aumento sostenido, mientras que PIN y Permanente presentaban inconsistencias a partir de junio. Dado que ya estábamos por aquí, decidí alargar un poco más el experimento, y ver hasta qué punto es predecible (y por lo tanto, podemos gestionar recursos y servicios) el número de identificaciones. Esto serviría un poco como práctica y, además, para explicar algunas cuestiones del estudio de series temporales. En principio, yo tenía mis ideas (más basadas en estudios descriptivos que predictivos). Ahora vamos a ver si se puede predecir el uso de servicios digitales.

Descomponiendo la temporalidad
Lo primero que debemos hacer para estudiar la temporalidad de estos tres servicios, es descomponerla en tres factores:
- Tendencia: es la línea que sigue a lo largo del tiempo el fenómeno observado.
- Estacionalidad: es la frecuencia con la que se repiten comportamientos a lo largo de cierto periodo
- Ruido: es los datos que se «salen» de la composición que hacemos de la tendencia y la estacionalidad. Es decir, si juntamos ambas partes, tendremos un valor, pues lo que se diferencia de ese valor, es el ruido.
La manera en la que integramos los tres elementos va a variar:
- si los sumamos hablamos de un modelo aditivo (la serie es resultado de tendencia x tiempo x ruido)
- Si los multiplicamos es un modelo multiplicativo (tendencia x estacionalidad x ruido)
El modelo miultiplicativo tiene más sentido cuando la estacionalidad y la tendencia tienen una cierta asociación, y se aplica a cuestiones como la economía y las finanzas, mientras que el modelo aditivo es más propio de elementos biológicos (agricultura, virus…)
Comparando servicios.
Ya habíamos hablado de la tendencia anteriormente
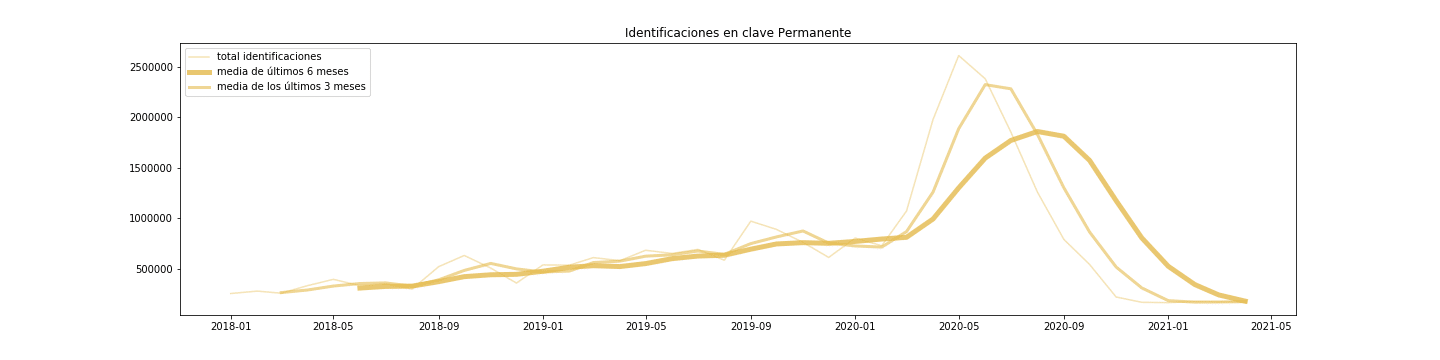
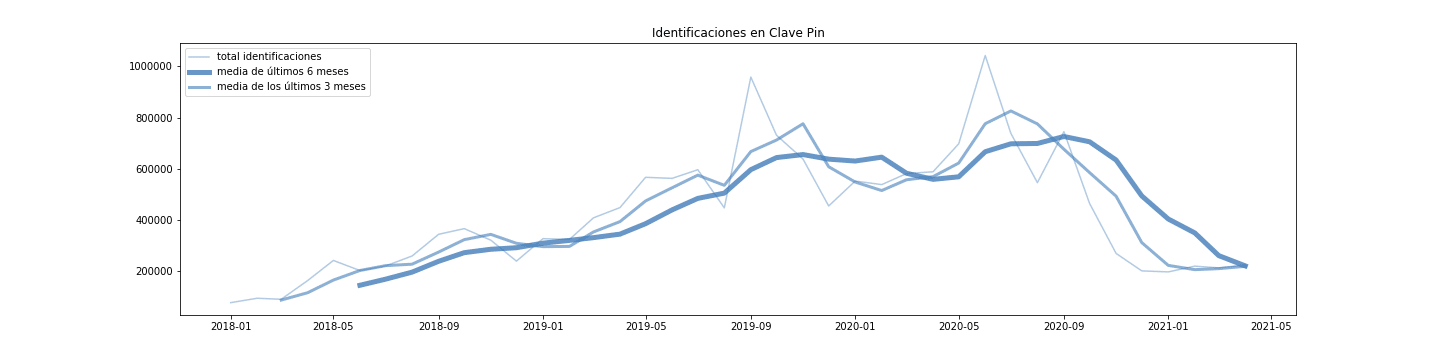
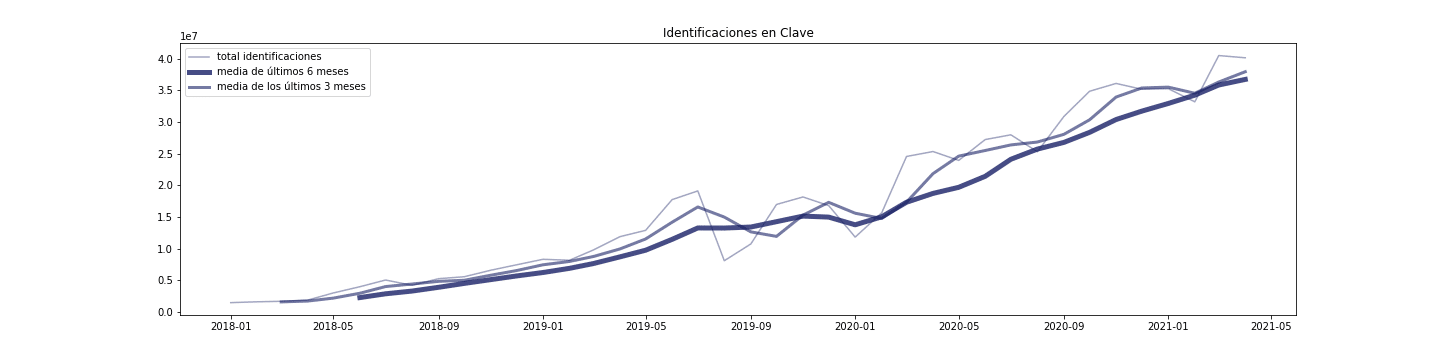
En todo caso, tras comprobar la distribución del ruido, parece más adecuado el modelo aditivo para clave, mientras que es mejor el multiplicativo para PIN y Permanente
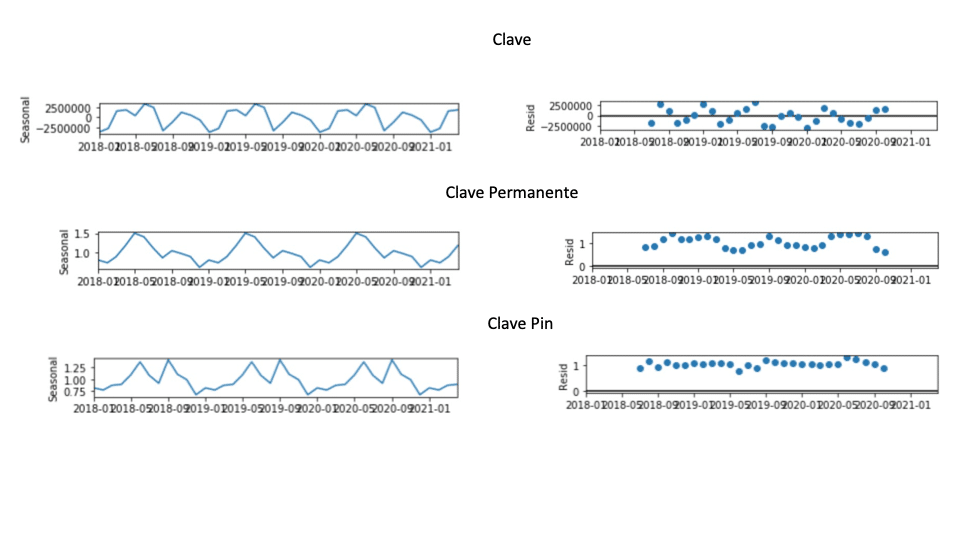
Si vemos los datos nos encontramos con algunas revelaciones:
- Clave tiene un ascenso estacional de marzo a agosto, una caída importante ese mes, y luego un aumento hasta octubre con una caída a partir de ahí hasta diciembre. Los residuales parecen tener un comportamiento más o menos consistentes.
- Clave Permanente tiene un pico desde mayo hasta julio, lego una caída importante que se recupera en septiembre. Todo apuntaría a periodos de aumento de la contratación (campaña de verano e inicio de curso).
- Clave PIN tiene dos clarísimos picos, entre mayo y junio y en octubre. Esto se debe a la declaración de la renta (junio) y, quizá, por el segundo pago de renta para no residentes (gracias Twitter).
Pero ¿Qué influye más, la tendencia o la estacionalidad a la hora de entender el uso de estos mecanismos?

Encontramos que la tendencia tiene una correlación muy fuerte con la evolución del uso. En todos los casos alcanza el 1 (valor máximo) mientras que, en el caso de la estacionalidad, vemos de todo. Desde el caso de clave Permanente, en el que su fuerza no es muy grande, en el caso de clave PIN sí que hay un impacto relevante. Es decir, a la hora de saber cuánta gente usa un mecanismo u otro, es más importante siempre saber en qué año estamos que en qué fecha, pero en el caso de PIN, la fecha también tiene bastante importancia.
Prediciendo el futuro de Clave
Hay dos principales mecanismos de predicción de series temporales:
- Autorregresión, que básicamente calcula como influye el paso del tiempo en un valor para proyectar el resultado. Si sabemos que ha 1000 usuarios más de clave para cada mes, en 3 meses habrá 3000 usuarios más.
- Media móvil, que considera el margen de desviación que hay entre la autorregresión y los valores reales para corregir este valor. Es decir, que si sabemos que sube de media móvil en torno a 1000 usuarios cada mes, pero que hay un error medio de unos 100 usuarios menos, es más probable que tengamos 2700 usuarios en 3 meses en lugar de 3000. Esto es más preciso, pero requiere que la desviación típica sea más o menos la misma a lo largo del tiempo (porque si no, esos 100 usuarios menos es porque un mes eran justo mil y al siguiente 200, quizá sea un poco impreciso).
Para ver si esto se da, vamos a ver si esto es así comparamos la media móvil de cada servicio con la desviación estandar. En la medida que vayan paralelas, será más fácil predecirlo. Si se separan será más complicado:
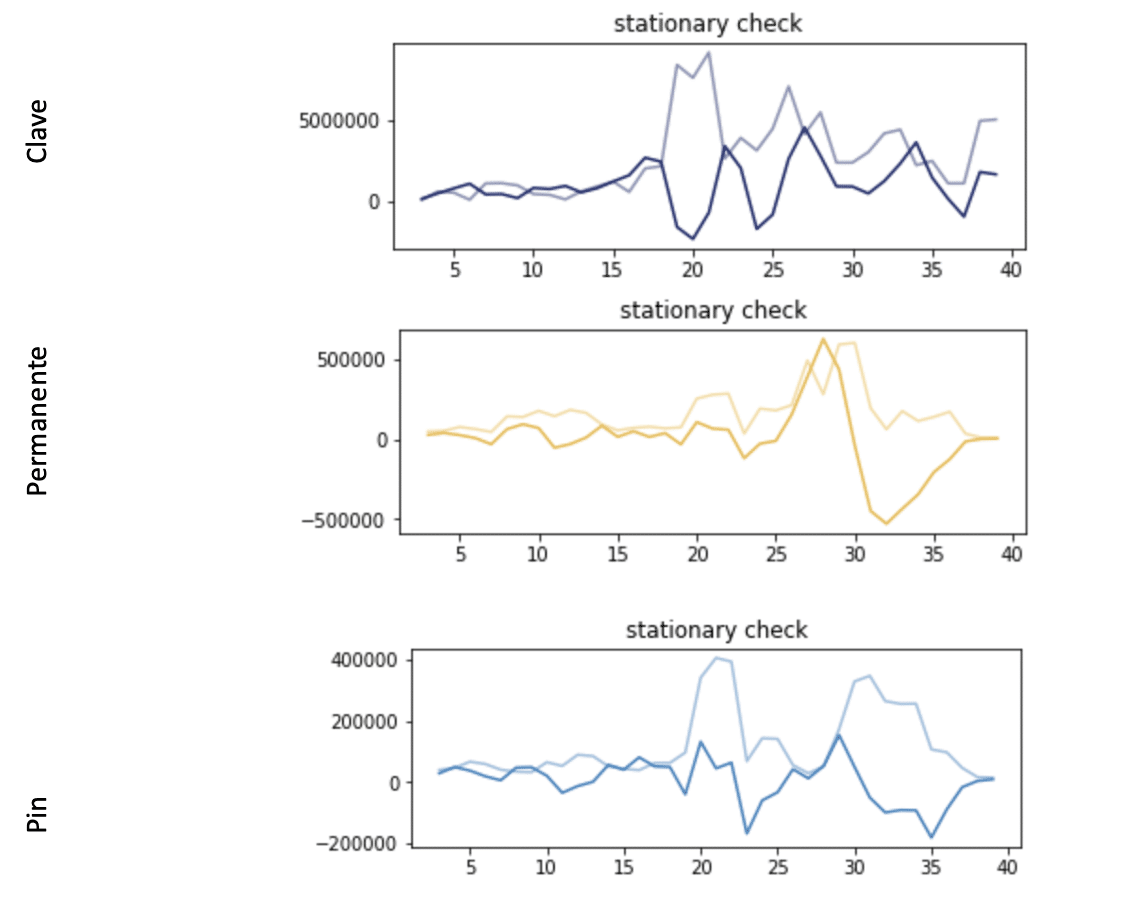
Como vemos, no hay una gran estabilidad a largo plazo, y por lo tanto, esto limita al modelo ARMA. Para ello utilizamos el modelo ARIMA. Este modelo integra la serie intentando garantizar la estacionariedad que permite funcionar al modelo ARMA. ¿Cómo lo sabemos? pues no solo porque hemos visto que la media circulante y la desviación van un poco por su lado, sino porque, como vimos en la autocorrelación, no hay mucha relación con los meses anteriores.
¿Qué podemos prever?
Tenemos los datos y tenemos el modelo (ARIMA) para los tres casos. ¿Qué nos hemos encontrado?
Pues bien, hemos podido observar lo siguiente:
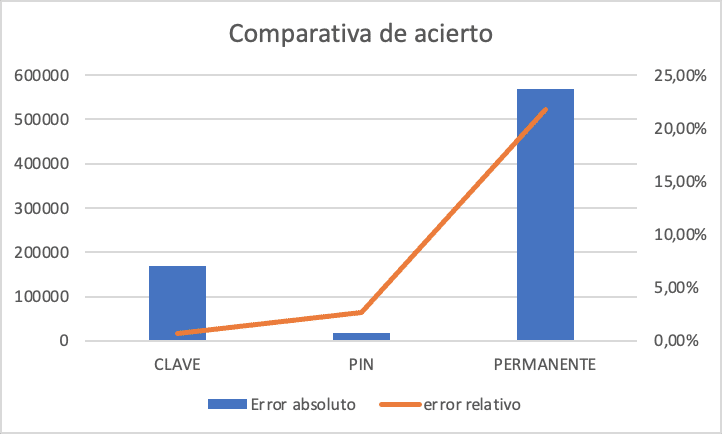
- Identificaciones por pasarela: tenemos un margen de error algo superior a 150000 casos, muchos, pero dada la magnitud de uso, hablamos de un margen de error del 0,2%. Nada mal.
- El caso de calve PIN tienen un error total de algo más de 18000 casos, que en términos relativos es del 2%, lo que tampoco está mal.
- Clave permanente si que muestra un margen de error en la predicción de más de 500000 casos y que es superior al 20% de margen de error estandar. Posiblemente, el pico de peticiones del IMV impide hacer una predicción más precisa, al menos con este modelo.
¿En qué se traduce esto? Pues en que podemos acertar con bastante certeza el uso de Clave para los próximos meses y, de manera relativamente aceptable el de clave PIN. Estos son los resultados de comparar la predicción con los datos reales.
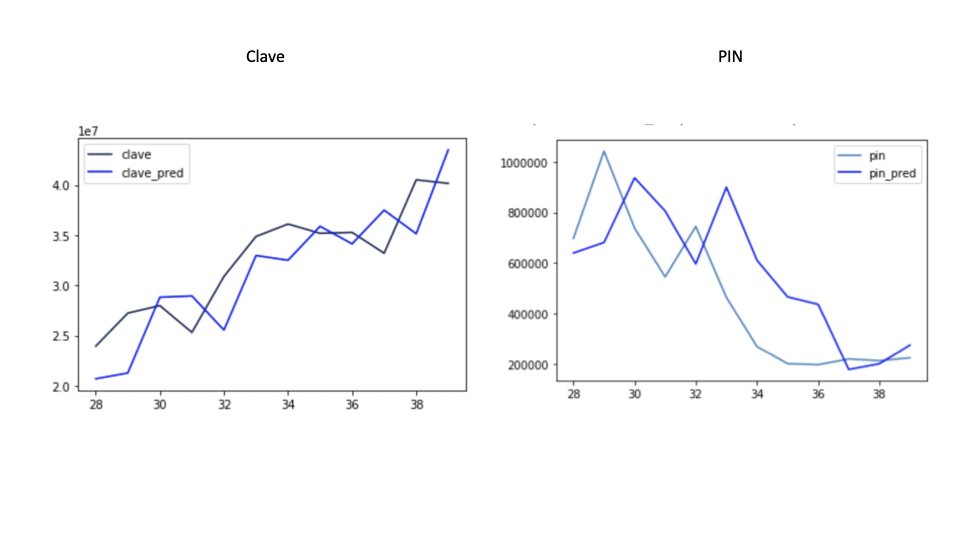
Podemos observar que ambos elementos, que vimos que estaban muy marcados por la tendencia (uno en ascenso y otro en descenso), varían en cuando a cómo se ajustan los valores predichos para Clave (a la izquierda) mucho más que a los de PIN (a la derecha). Esto es lo que significa el margen de error: habiendo este desajuste, su tamaño cambia sustancialmente. Dicho de otro modo, podemos predecir de manera bastante certera el número de identificaciones con Clave los próximos meses, mientras que en el caso de PIN, hay una aproximación alta, pero con un error relativo más alto.
Dos leyes para el uso de la IA en los Servicios Públicos
Imaginaros que estáis en la calle viendo una calle con dos carriles en el mismo sentido. En uno de ellos va un coche rápido a una velocidad constante. En el otro, ves un coche que va un poco a trompicones, a veces va casi parado, luego pega un acelerón, luego se queda calado… Nos va a resultar mucho más fácil anticipar cuando va a llegar el coche que va rápido al semáforo que el que va a trompicones. Esto es lo que nos pasa en este caso y, muy probablemente, en muchos de los servicios públicos. Como hemos visto, la convocatoria del IMV ha hecho imposible aplicar un modelo predictivo fiable. Esto nos deja dos principios importantes respecto al uso de la IA para los servicios públicos.
- Un sistema se vuelve más predecible en la medida en la que su uso se hace más amplio. Esto no es tanto por el hecho de que más gente es más previsible, como por el de que una mayor cantidad de usuarios posiblemente haga una mayor diversificación de perfiles (distintos motivos por los que se usa) haciendo que cuando un tipo de público lo usa menos, otro público lo usa más. Es como cuando se diversifican acciones de bolsa: reducimos ganancias, pero es menos probable perder.
- Los servicios públicos con un uso residual o de nicho son muy susceptibles a irregularidades en su demanda. Este segundo elemento que ya conocíamos hace años por el estudio de los portales de transparencia, se ve de nuevo aquí. Clave Permanente (y hasta cierto punto PIN), tenían un crecimiento más o menos estable hasta que entraron un montón de personas a usarlo de manera temporal. Esto posiblemente generó problemas de provisión del servicio y, además dificulta cualquier predicción a medio plazo.
Conclusiones
La sensación es que hay servicios que parecen un coche que tiene problemas de embrague. A veces entra la marcha, va dando saltos, acelera, y se cala. No podemos culpar a quien mira en el semáforo de no poder predecir, sino que tenemos que pensar que deberíamos arreglar el embrague para que el tráfico fuera normal. Es decir, si queremos aplicar la IA a servicios públicos digitales, no sólo es que tengamos que evitar sesgos en el diseño algoritmo, sino que, además, debemos hacer que su consumo sea lo más masivo y diverso para que la predicción sea posible y, además real.
En resumen: muy bien a la IA en los servicios públicos, pero si queremos una IA útil (y real) más nos vale ponernos a hacer que los servicios públicos que generan los datos para esa IA estén ampliamente demandados y diversamente representados, o nos moveremos entre predicciones muy desajustadas o decisiones extremadamente sesgadas.
