Volvemos al mundo de la ciencia de datos aplicada a Administraciones y Servicios Públicos. Después de haber hablado de analitica predictiva y de tipos de datos ahora vamos a hablar de modelos predictivos. Vamos a empezar por dos casos muy básicos que conocemos de pasearnos por internet, hacer compras o ver las redes sociales. Vamos a ver cómo usamos la predicción basada en objetos y la basada en barrios, que se aplica más a las personas.
Dos modelos predictivos a partir de datos: objetos y barrios
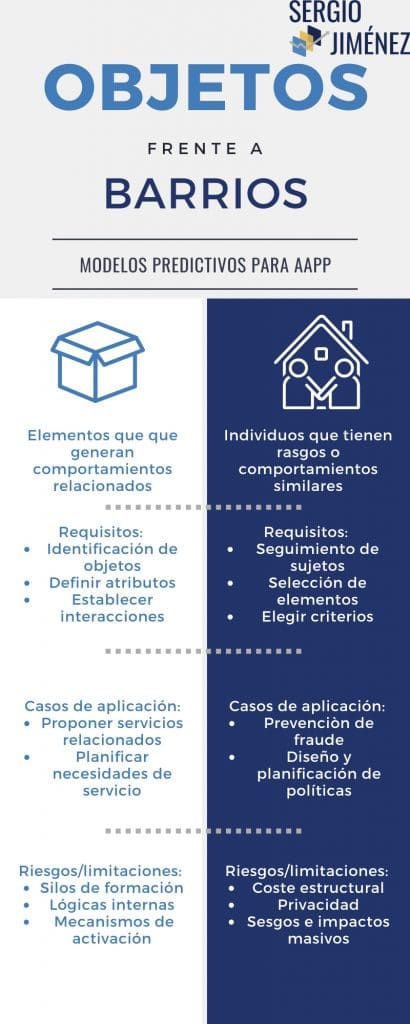
Predicción basada en objetos.
Empecemos por el modelo más básico y simple de predicción, que es el basado en objetos. Normalmente cuando llegas a hacer una compra en una web encuentras qué otros productos se han comprado a la vez. Si compras unas pinzas de barbacoa, te dirá que se compra normalmente con un kit de limpieza, carbón o un termómetro. Si en un periódico lees una noticia sobre la CNMC, te aparecerá que te puede interesar leer artículos sobre el crecimiento económico, Uber y el Frob (por poner un ejemplo). ¿Cómo se hace esto?

El mecanismo consiste en estudiar objetos que se consumen de manera simultánea o con un elemento común (en la misma sesión, en un flujo de navegación, en búsquedas internas en una web…) y ver cuántas veces coinciden. De esta manera, si alguien compra unas pinzas de barbacoa y un termómetro, esto lo veremos en la lista del carrito y ya tenemos una posible sugerencia. Si alguien tras buscar competencia en un periódico acaba leyento un artículo sobre Uber, asociaremos ambas etiquetas. La predicción se basa en dos objetos que tienen un consumo asociado e identificable.
Predicción basada en barrios.
Ahora vamos a otro ejemplo de la vida cotidiana. Una persona (llamemosla Anastasia) sigue en su cuenta de twitter a perfiles de determinado tipo (político, deportivo, cultural, etc)… y dentro de ellos tiene una mayor interacción (le da al me gusta, retuitea, responde, cita) a determinado tipo de perfiles. Ahora imaginemos que otra persona (llamemosla Sinforiano) que tiene menos actividad en twitter pero sigue, más o menos, el mismo tipo de perfiles de un ámbito (por ejemplo, políticos) e interactúa de manera similar con algunos de los tuits con los que Anastasia interactúa. Twitter posiblemente estime que si muestra a Sinforiano algunos de los tuits con los que interactúa Anastasia es probable que él interactúe con ellos. Esto significa que Anastasia y Sinforiano están en el mismo barrio.
El sistema de predicción basado en barrios consiste en agrupar elementos (en este caso usuarios) por aspectos de afinidad que permita preveer comportamientos similares. Cuando hablamos de «algoritmos» hablamos muy a menudo de esto.
¿Qué necesitamos para hacer predicciones?
Tenemos dos modelos predictivos de trabajo. El primero se centra en elementos estáticos que controlamos y cuya unidad de análisis es la interacción explicita.
Predicción basada en objetos.
Para poder establecer predicciones basadas en objetos necesitamos:
- Identificar los objetos de transacción. A veces esto es sencillo (un artículo, un producto de catálogo), pero otras veces no lo es tanto. Por ejemplo, a la hora de acceder a elementos de consumo de contenidos saber si es una serie, o un capítulo, o 5 minutos son elementos a tener en cuenta.
- Establecer los atributos de los objetos a relacionar. Cuantos más atributos tengamos definidos de los objetos, más posibilidades de relación. Por ejemplo, si solo tenemos los datos de compra, cuando alguien compre pinzas de barbacoa solo aparecerán lo que compran junto a estas. Sin embargo, si tenemos otros atributos (por ejemplo, que son artículos de barbacoa, de jardín y tiempo libre, o que se compra más en verano), más objetos podemos asociar
- Un sistema que permita establecer interacciones entre los objetos. Si tenemos objetos y etiquetas, podemos buscar los elementos de interacción que permita sugerir su uso: compras simultáneas, categorías relacionadas, precios similares, tiempo de envío…
Predicción basada en barrios.
La predicción basada en barrios precisa otro tipo de elementos.
- Identificación y seguimiento de personas. Es necesario saber quién hace qué cosas, cuanta mayor cantidad de información, más capacidad de buscar interacciones. En twitter saben quiénes son Sinforiano y Anastasia y lo que hacen (esto incluye los datos actitudinales)
- Definir los elementos a analizar. Una persona que usa un servicio tiene cientos de datos que podemos mirar y elegir es complicado. Es preciso saber qué elementos vamos a analizar para establecer los barrios (a quién sigue, qué hacen con el tuit, cuándo se conectan, quiénes les siguen…)
- Establecer los atributos por los que vamos a definir los barrios: ¿Qué elementos hacen que Anastasia y Sinforiano sean del mismo barrio? En este caso es fácil, coinciden en perfiles que siguen y lo que hacen, pero cuanto más perfilados están los barrios, más necesario es buscar relaciones no evidentes. Por ejemplo, seguir determinados perfiles, o tiempo que se hace scroll en la App pueden decirnos mucho del perfil de los usuarios y diferencias a Anastasia de Sinforiano para proponerles elementos diferenciados.
Esto se traduce en más capacidad de almacenamiento, gestión y cómputo de datos.
¿Cómo podemos usar esto en las administraciones públicas?
Os habréis dado cuenta que hasta ahora no hemos hablado de lo público, pero muy posiblemente, ya estaréis pensando qué podemos hacer con estos datos. Así que vamos a ver.
Los modelos predictivos basados en objetos son más «ligeros» y sencillos de hacer. Basta con tener claro qué elementos están relacionados. Por ejemplo, sabemos que si una persona usa una escuela infantil es muy probable que use un campamento de verano, así que podemos calcular cuántas plazas necesitamos y a quién avisar de que se abren las inscripciones.
El sistema basado en barrios requiere un mayor esfuerzo técnico, pero ofrece un alcance más alto. Por ejemplo, cuando una agencia de recaudación de impuestos sabe que determinados perfiles profesionales que se mueven en determinado nivel de ingresos, posiblemente tendrá determinados nivel de gastos. Cuando los vecinos de este barrio (perfil profesional con determinados ingresos) tiene una discrepancia importante en gastos, puede lanzar una inspección. Más allá de estos aspectos «fiscalizadores» podemos pensar otros menos punitivos. Por ejemplo, si suponemos que familias con determinado tipo de estudios tiene hijos dentro de una horquilla de edad, podemos usar el sistema de barrios para prever la necesidad de escuelas infantiles y la ubicación de estas a partir de los datos de padrón (por poner otro ejemplo).
¿Hasta dónde llegan la aplicación de estos modelos?
Ahora bien, todo parecen fiestas y alegrías hasta que toca pensar en cómo encaja esto con la acción (y la naturaleza) de las AAPP. Aquí tenemos algunos elementos a considerar:
Predicciones basadas en objetos
- Silos de información y de servicios. El primer punto corresponde a la naturaleza de la Administración y su funcionamiento. Resulta muy complicado que una administración en la que suele haber poco intercambio de datos (ya no digo entre distintas administraciones, sino dentro de una misma) , podamos establecer quién accede a qué servicios. Por ejemplo, que la concejalía de educación (que lleva escuelas infantiles) comparta datos de familias con la de deportes (que lleva parte de los campamentos de verano) no es algo que haya visto yo de manera muy frecuente.
- Conceptos de lógica interna. Es relativamente normal que cuando la administración cataloga servicios y objetos siga su lógica de procedimientos internos no siempre compatibles con otras administraciones y, menos aún, con la ciudadanía. En este sentido, la integración de objetos es realmente complicada.
- Mecanimos de activación. En términos generales, estos dos antecendentes se complican con el hecho de que la gente suele tener contacto con las administraciones de manera asincrona y fragmentada. Usa un sevicio (o unos pocos) cada vez en distintas administraciones. Sin una unificación de catálogo e intercambio de información, lo más lejos que podemos predecir es lo que puede ofrecer cada agente por sí sólo.
Predicciones basadas en barrios.
Las predicciones basadas en barrios no dependen tanto de la naturaleza de la administración y sus silos, sino de la disponibilidad tecnológica y algunas consideraciones éticas de peso.
- Disponibilidad de recursos y medios. Tener todos los datos para tener unos barrios «fiables» no es una bagatela. Todos pensamos en lo bien que lo hacen Netflix o Amazon, pero pocas veces pensamos lo que le cuesta en dinero a Netflix o Amazon ser así. Requiere teras de datos de manera constante, científicos de datos, una importante inversión en I+D…
- La privacidad. Los barrios requieren un seguimiento importante de los datos de las personas y eso es un elemento a tener en cuenta. Es cierto que las administraciones están muy beneficiadas en la autorización del tratamiento de cara al RGPD (no lo necesitan), pero la cuestión es hasta que punto la analítica predictiva es un tratamiento necesario para los servicios. La anonimización de datos permite llegar, quizá, a algunos puntos (prever servicios o infraestructuras), pero limita de manera importante la creación de servicios proactivos y personalizados. No se trata de decidir ya si es posible o deseable, pero si de establecer las bases para un pacto entre poderes públicos y ciudadanía de hasta dónde y qué datos.
- Los posibles sesgos. Los algoritmos sesgados son una de las cuestiones más importantes con las que tendrá que lidiar la sociedad en el futuro próximo. De hecho ya lo hace ahora. En mi opinión (y es algo muy personal) no existe el algoritmo «no sesgado» porque la selección y ordenación de datos no deja de ser una concepción simbólica e interpretativa de la realidad. Pues bien, es lógico que a la hora de construir barrios la selección o descarte de dimensiones directas (raza, renta, género, vivienda, etc) o indirectas (cosas que no hacen personas de determinada raza, renta, género o vivienda, por ejemplo), así como la propia finalidad del barrio (para tener más servicios, planificar más, mantener la cohesión social, amentar la inversión…) inciden de manera muy significativa en la realidad y la política.
Entonces ¿Qué se puede hacer?
En mi opinión las AAPP no pueden demorar más dar este salto hacia el uso de la ciencia de datos y las predicciones. Cada día que pasa aumenta la distancia de un sector privado más potente que puede sustituir (con importantes riesgos) a lo público, tal y como está ocurriendo con las herramientas de rastreo del COVID o la planificación urbanística en Toronto.
Esto significa empezar a entender qué buscamos y qué tipos de modelos y predicciones aportan valor público a la ciudadanía. Esto no está exento de problemas, polémicas o debates, pero, desde luego un debate nunca es más fácil por postponerlo.
Creo que deberían empezar a plantearse una definición de los objetos (servicios, acciones, trámites o procedimientos) y las dimensiones que los rodean y a definir barrios para algunos tipos de servicios, aunque sea de manera sectorial (imaginad lo que podríamos hacer con la exclusión o la dependencia con un trabajo así). Pero ya iremos hablando de lo que se necesita para eso.
